How We Ate Thousands Of Hours Of YouTube with Trigger.dev
Learn how we built an automated content intelligence system that analyzes thousands of YouTube videos to identify emerging trends and shape content strategy using Trigger.dev
Published: February 25, 2025You can’t teach what you don’t know, and you can’t know what you’re not constantly learning yourself. The half-life of technical knowledge is shrinking, and yesterday’s breakthrough is tomorrow’s baseline.1×This challenge isn’t unique to me—it’s something Fabian and his team at [Redacted] were determined to solve. As a learning platform, they needed to ensure their educational content remained relevant, fresh, and aligned with industry trends.Their goal was to create content that truly followed the zeitgeist and promoted progression by keeping up with everything happening in the digital space.
How far behind are most content teams when it comes to emerging trends?
Most content teams lag 3-6 months behind cutting-edge topics, especially in fast-moving fields like LLM tooling and models, making their educational content outdated by the time it’s published.
The traditional content research workflow most content teams are using has fundamental flaws:
Massive time investment: Content researchers spent 60% of their time just trying to stay current
Inconsistent analysis: Different researchers extracted different insights from the same content
Limited coverage: They could only monitor about 25 channels regularly
High latency: Content in specific sectors lagged, anywhere from 3-6 months behind cutting-edge topics; a no-go when dealing with the latest LLM tooling and models.
Subjective prioritization: Topic selection was based on what “felt” important rather than data — not a problem for the team and their refined taste, but lacking a system to move faster.
Fabian’s team knew they didn’t want to continue with manual methods and accept the risks of being perpetually behind. They needed to find a technical solution to automate their research process.
Why We Chose Trigger.dev: Simplifying Distributed Processing
Why choose Trigger.dev over building your own job queue system?
Trigger.dev provides built-in queue management, native batch processing, and robust error handling without the complexity of managing Redis instances or setting up dead-letter queues that often fail at 3 AM.
From previous projects, I’ve spent countless nights wrestling with job queues. Most developers have horror stories about production queue systems going down at 3 AM because Redis ran out of memory, or jobs silently failing because no one (ahem) set up proper dead-letter queues. You know the pain if you’ve ever built a system that needs to process thousands of anything.For this project, we chose Trigger.dev from the start, which proved to be an A* decision. Instead of spending weeks setting up infrastructure, we could focus entirely on solving the content analysis problem. Trigger.dev offered:
Built-in queue management: No need to manage our own Redis instances or job persistence
Native batch processing: Support for processing hundreds of items in parallel
Concurrency controls: Fine-grained control to prevent API rate limiting
Robust error handling: Automatic retries and detailed error reporting
Development simplicity: Focus on business logic rather than infrastructure
Our implementation was refreshingly straightforward:
By offloading the DevOps complexity to Trigger.dev’s team (who are incredible at what they do), we could focus on building the solution that Fabian’s team needed. Trigger.dev has been a fantastic resource throughout this project and I thoroughly recommend baking it into your workflows like ours.
What’s the benefit of a one-week proof of concept sprint?
Short sprints allow clients to test automation solutions without committing to a full build, letting them see real results and determine if the approach fits their needs before making a larger investment.
This project was designed as a one-week proof of concept sprint. The reason we do these short sprints is pretty simple: it allows clients to quickly determine whether an idea has legs without committing to an entire build. In a very short time, Fabian and his team could test the waters, see what life is like in the automation lane, and decide after some rigorous testing whether it was the solution for them or if we should go back and try something else.Our proof of concept focused on building a core pipeline architecture:
Channel Discovery: Monitors YouTube channels and detects new videos
Video Processing: Extracts transcripts and metadata from each video
Content Analysis: Uses AI to extract structured insights from the transcript
Insight Storage: Organizes and stores the processed insights
Content Retrieval: Provides filtered access to processed content by various criteria
This approach allowed us to demonstrate the potential of automation without building a complete end-to-end solution.
Multi-level Batch Processing: The Key to Scalability
How much faster is automated batch processing compared to manual analysis?
The system processes 200 videos in ~30 minutes versus 100 hours manually—a 200x speedup that transforms content research from weeks of work into a quick automated task.
One of the key technical innovations in our system is the use of multi-level batch processing for efficient scaling:
Level 1: Process multiple channels concurrently
Level 2: For each channel, process multiple videos concurrently
This approach allows us to process hundreds of videos simultaneously, dramatically reducing the time required to extract insights:
Manual approach: 200 videos × 30 minutes per video = 100 hours (or 2.5 work weeks)
Our system: 200 videos processed in parallel = ~30 minutes total
This **200x **speedup demonstrates how automation could transform the content research process for Fabian’s team.
What makes AI content analysis more effective than simple summarization?
Structured extraction using schemas captures specific business-relevant data like talking points, categories, and actionable learnings, rather than generic summaries that don’t provide strategic value.
The core of our insight extraction uses AI to analyze video transcripts and extract structured information:For each video, we extract:
Talking Points: Key topics discussed in the content
Our initial implementation used a much simpler prompt that just asked for a summary and keywords. The results were disappointing—vague, generic summaries that didn’t capture the technical depth needed. After several iterations, we landed on a more structured approach:
When I describe this architecture to other engineers, their first reaction is usually, “That seems straightforward.” And that’s exactly the point. The architecture is straightforward—almost deceptively so. The complexity lies not in the conceptual design but in the operational details: handling hundreds of parallel processes, managing API rate limits, recovering from failures, and processing gigabytes of transcript data.
Why visualize system flows in automation projects?
Flow diagrams help stakeholders understand how different components interact, making complex automated processes transparent and easier to optimize or troubleshoot.
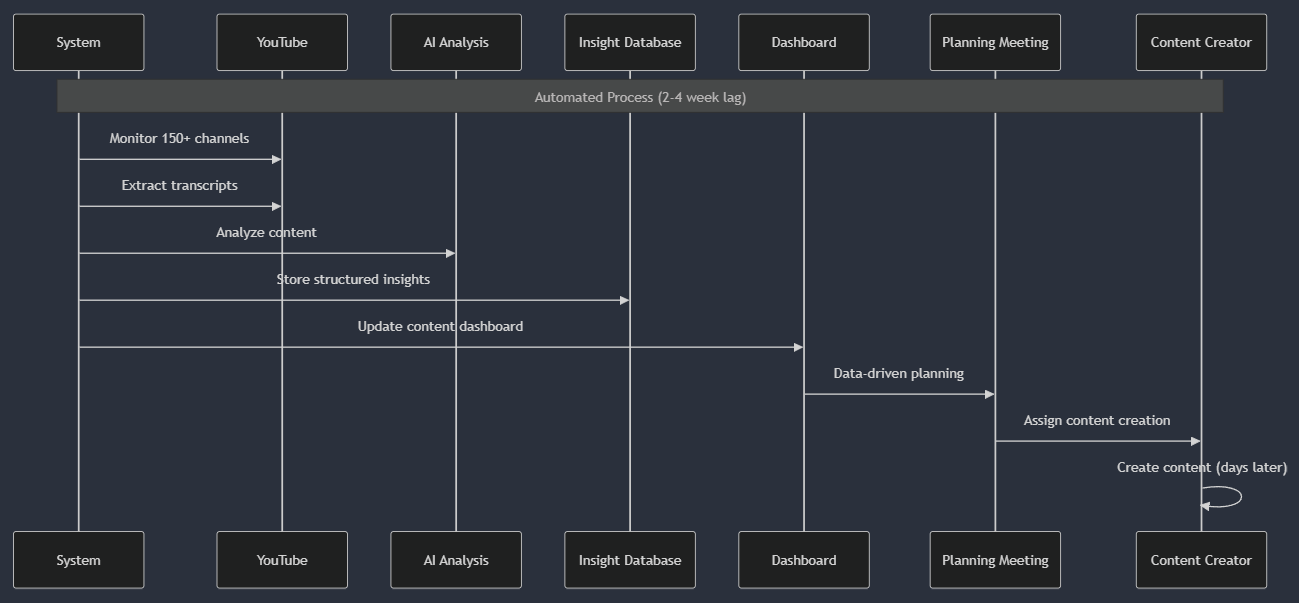
To truly understand how our content intelligence system works, it helps to visualize the sequence of interactions between different components. Let’s examine some of the key flows that make this system possible.
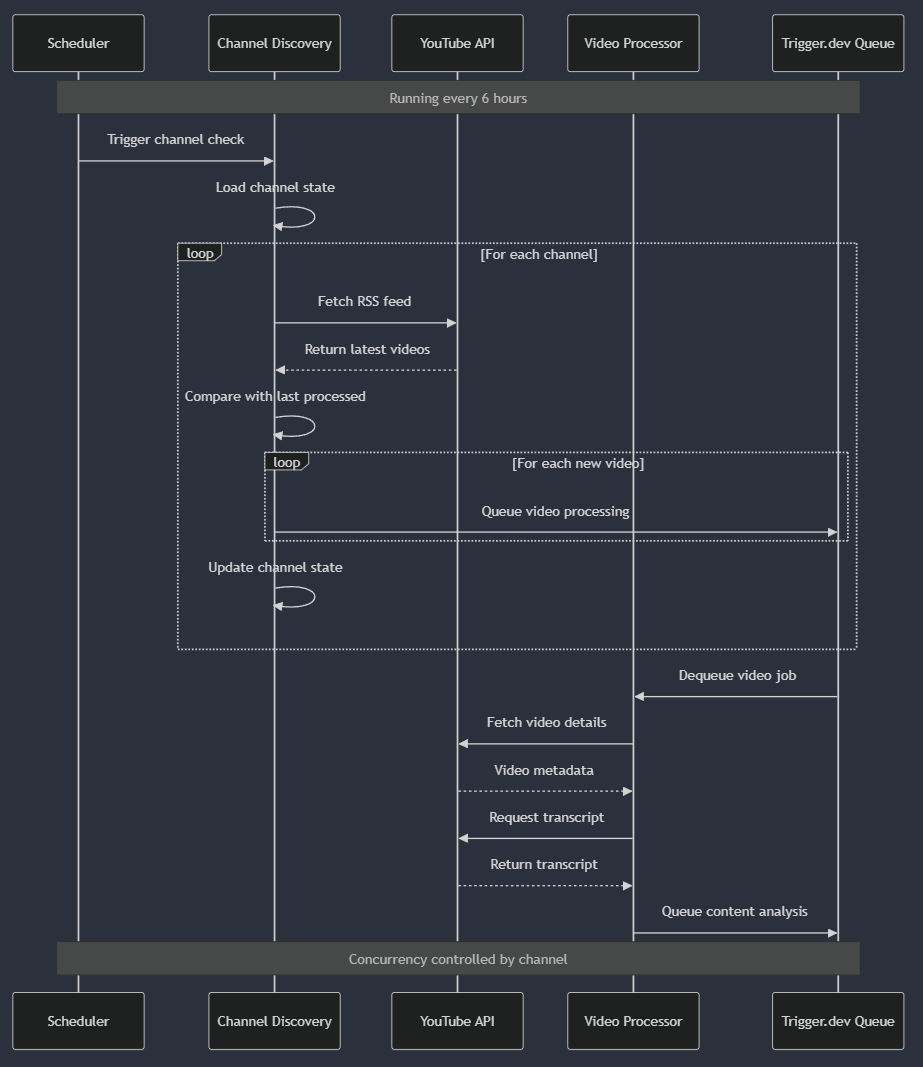
The first critical flow is how our system discovers and initiates processing for new content:This diagram illustrates how we manage the discovery process with efficient batching and state tracking. The system maintains a record of the last processed video for each channel, allowing it to identify only new content that needs processing efficiently.
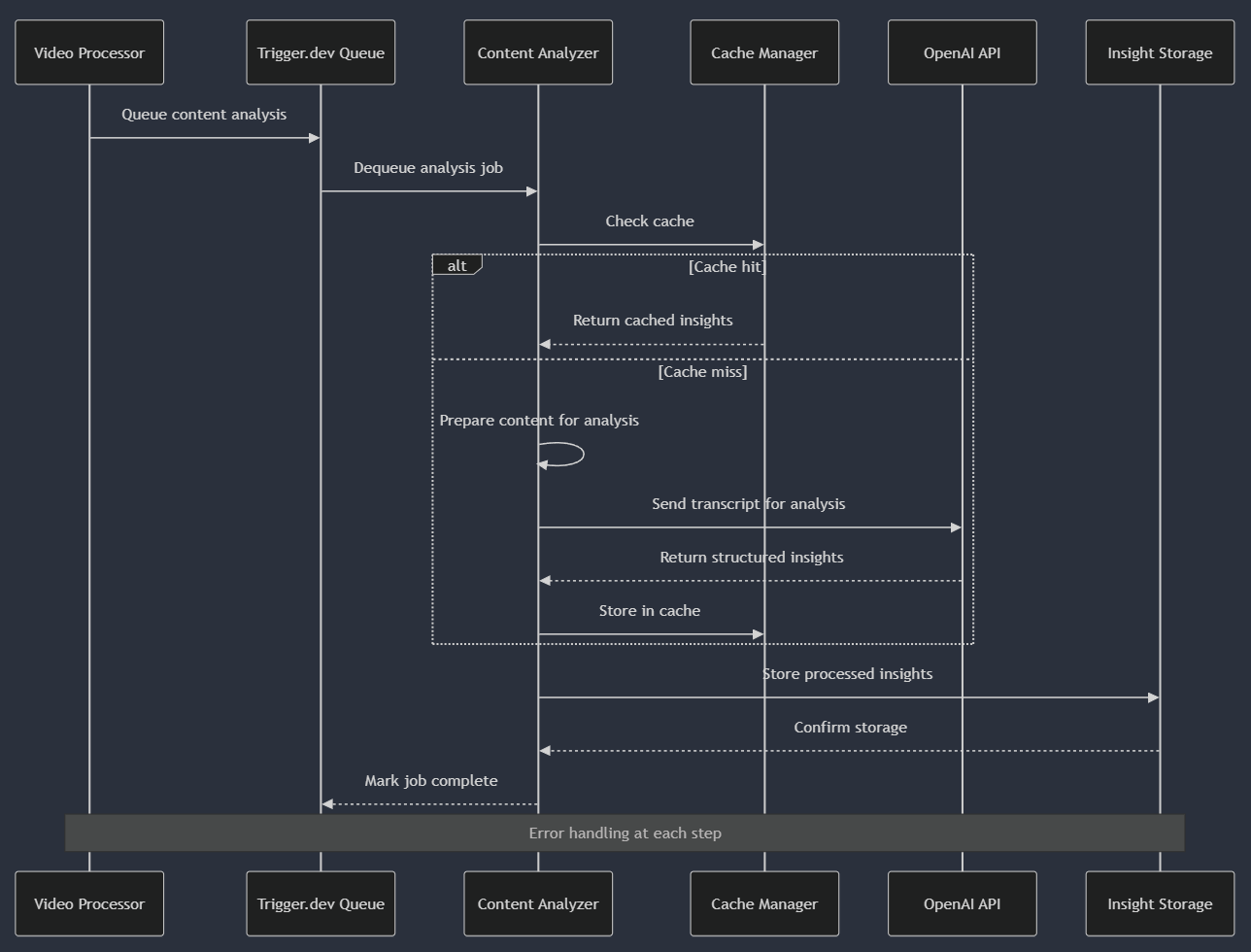
Once a video and its transcript are retrieved, the content analysis process begins:This flow demonstrates how we optimize performance through caching while ensuring reliable processing. The cache dramatically reduces both processing time and API costs for repeated or similar content.
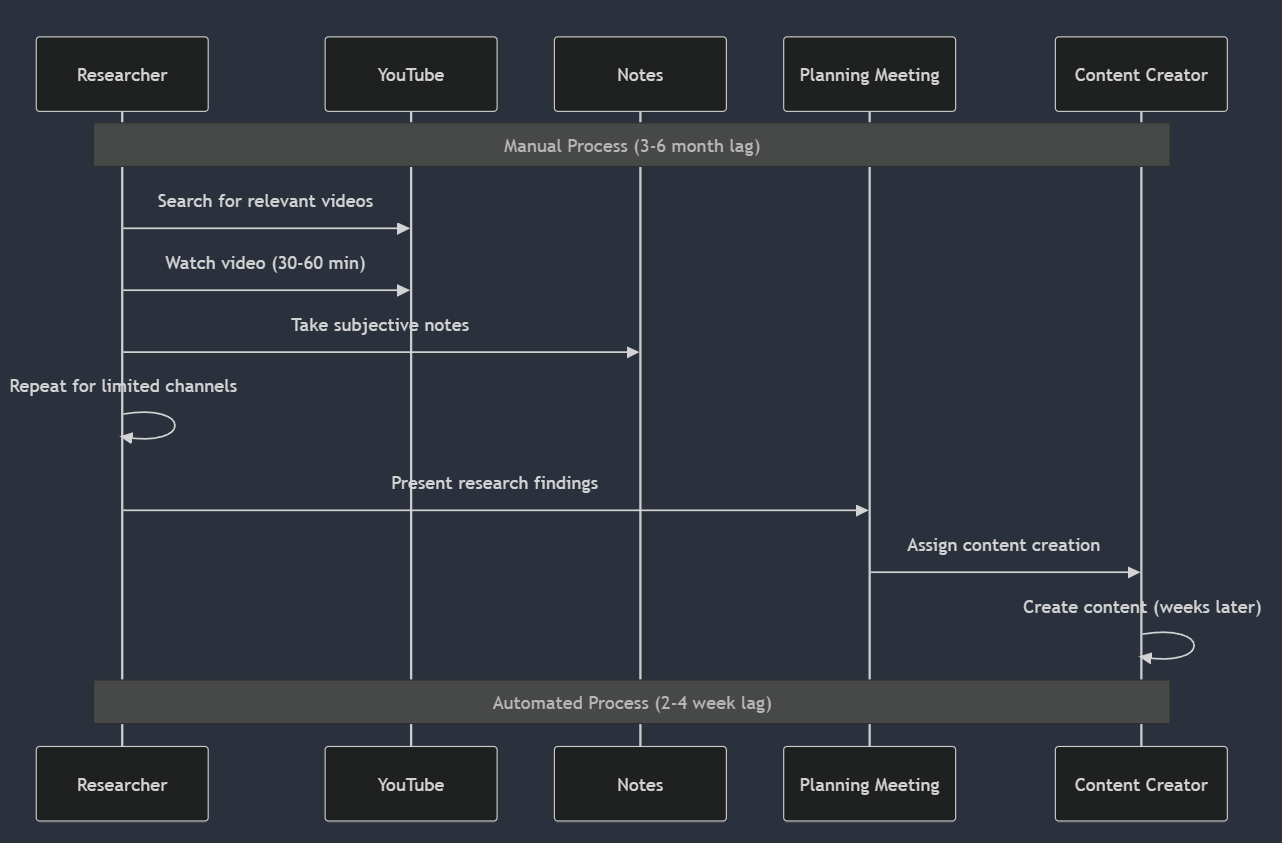
To appreciate the efficiency gains, let’s compare the traditional manual research flow with our automated system:
Before: Cumbersome, desystematised, dirty
After: Automation utopia with a 200x increase
These comparative flows highlight how automation has fundamentally changed our research process. We cover more ground and process content more quickly and consistently, dramatically reducing the lag between industry developments and our learning content.
Why This Works: The Challenge of Staying Current with Frontend Frameworks
Okay, great. You can skim content. Why does that matter? Here’s an example. Consider how quickly the React ecosystem evolves. New patterns, libraries, and best practices emerge constantly. A manual research process would struggle to keep up with:
Core React updates and new features
Emerging patterns and community conventions
Framework integrations (Next.js, Remix, etc.)
State management solutions
Performance optimization techniques
Server component developments
With our automated system, these developments could be tracked as they emerge, allowing content creators to plan and develop educational material that stays relevant to current industry practices—instead of teaching yesterday’s patterns.
What are the biggest technical hurdles in large-scale content processing?
API rate limiting, processing enormous transcripts, and ensuring reliability across thousands of videos require careful concurrency control, content chunking, and comprehensive error handling.
YouTube’s API has strict rate limits that could potentially block our processing. We addressed this by:
Implementing channel-based concurrency controls
Using batch processing to optimize API usage
Storing processing state to avoid redundant operations
// Channel-based concurrency controloptions: { concurrencyKey: channelId, // Group by channel queue: { name: "youtube-channels", concurrency: 5, // Process up to 5 channels concurrently },}
In a system processing thousands of videos, failures are inevitable. We implemented:
Comprehensive error handling with structured responses
Detailed logging for debugging
State tracking to resume interrupted processing
Again, Trigger.dev made this easy. Deceptively so. Proof of concept Skunkworks projects require extreme delivery speed and accuracy over very short bursts. Trigger.dev is one of the rare tools that does exactly that.
The Universal Content Adapter Pattern: Designed for Expansion
How do you build systems that can easily add new content sources?
The Universal Content Adapter pattern standardizes how content is extracted, normalized, processed, and stored, making it simple to add new platforms with just a few lines of code.
While our initial implementation focused on YouTube content, we designed the architecture to extend to other content sources easily. We implemented a “Universal Content Adapter” pattern:
interface ContentAdapter<T, U> { // Extract content from source-specific format extract(source: T): Promise<RawContent>; // Normalize to unified content model normalize(raw: RawContent): UnifiedContent; // Process content through insight pipeline process(content: UnifiedContent): Promise<ContentInsights>; // Store results in format suitable for source store(insights: ContentInsights, metadata: U): Promise<void>;}
This pattern makes it very straightforward to add new content sources, as they all go through the same processor. We can add new sites, YouTube channels, articles, substacks, etc, with just a couple of lines, and Trigger.dev makes this extremely simple because of how its task system works with queues.
Potential Impact: From Manual to Automated Research
What’s the projected impact of automating content research?
Teams could reduce research time from 60% to 15% of creators’ time while monitoring 800+ channels instead of 25, enabling content that’s 1-2 weeks behind cutting edge instead of 3-6 months.
Based on our proof of concept, we projected how this system could transform Fabian’s team’s content creation process:Before Automation (Current State):
Content research consumes 60% of creators’ time
They monitor 25 YouTube channels regularly
Content planning is based on subjective impressions
Content is typically 3-6 months behind the cutting edge
After Automation (Projected):
Content research could be reduced to 15% of creators’ time
They could monitor 800+ YouTube channels automatically
Content planning could become data-driven, based on topic frequency and trends
Supporting learning content could be come out the same week, or even same day, as published. With most topics being 1-2 weeks at maximum behind the cutting edge.
This transformation would allow their creators to focus on what they do best—creating engaging, nuanced learning experiences—rather than spending most of their time just trying to stay current.
What comes after a successful automation proof of concept?
Next steps include building user interfaces, expanding to additional content sources, enhancing AI analysis, implementing feedback loops, and integrating with existing content management systems.
While our one-week proof of concept was successful in demonstrating the potential of an automated content intelligence system, there are several next steps to move towards a production solution:
Building the content dashboard: Developing a user interface to visualize trends and insights
Expanding to additional content sources: Adding LinkedIn, Twitter, and technical blogs
Enhancing the insight extraction: Further refining the AI analysis for specific content types
Implementing user feedback loops: Allowing content creators to rate and improve insights
Integrating with existing content management systems: Streamlining the workflow from insight to content
Lessons Learned: The Balance of Automation and Expertise
What’s the key lesson about automation and human expertise?
Automation should scale research capabilities so experts can focus on higher-level analysis and teaching, not replace editorial judgment—it’s about finding the right balance between efficiency and human insight.
Throughout this proof of concept, we’ve learned several key lessons about content intelligence automation:
Focus on core problems, not infrastructure: Tools like Trigger.dev let us spend time on our actual content analysis problems rather than queue management
Pipeline architectures provide flexibility: Breaking complex processes into composable tasks makes the system more resilient and extensible.
Smart concurrency is crucial for scaling: Understanding resource constraints and applying targeted concurrency controls is essential for reliable scaling.
Structured analysis yields better results: Providing structure to AI analysis produces more consistent, actionable insights.
Universal adapters enable expansion: Our design makes it very straightforward to add new content sources, and they all go through the same processor. Trigger.dev simplifies scaling with its task system and queues.
The most important lesson was finding the right balance between automation and human expertise. The system isn’t meant to replace editorial judgment—it’s designed to scale research capabilities so experts can focus on higher-level analysis, curation, and teaching.
How can businesses start exploring automation solutions?
A one-week proof of concept sprint lets teams test automation’s potential for their specific workflow without committing to a full build, providing quick validation of whether automation is the right solution.
How much faster is automated content analysis compared to manual research?
The system processes 200 videos in approximately 30 minutes versus 100 hours manually—a 200x speedup. This transforms content research from weeks of work into a quick automated task, allowing content teams to focus on creating rather than constantly trying to stay current with industry trends.
Why did you choose Trigger.dev over building your own queue system?
Trigger.dev provides built-in queue management, native batch processing, and robust error handling without the complexity of managing Redis instances or setting up dead-letter queues. Having spent countless nights wrestling with production queue systems failing at 3 AM, we chose to offload DevOps complexity to experts and focus on solving the content analysis problem.
What makes structured AI content analysis more valuable than simple summarization?
Structured extraction using schemas captures specific business-relevant data like talking points, categories, and actionable learnings rather than generic summaries. Our initial simple prompts produced disappointing, vague results. The structured approach with defined schemas ensures consistent, actionable insights that content creators can actually use for strategic planning.
How does the multi-level batch processing architecture work?
Level 1 processes multiple channels concurrently, and Level 2 processes multiple videos per channel concurrently. This parallel processing approach allows us to handle hundreds of videos simultaneously instead of processing them sequentially, dramatically reducing the total time required from weeks to minutes.
What are the biggest technical challenges in large-scale content processing?
The main hurdles are YouTube API rate limiting, processing enormous transcripts from hours-long videos, and ensuring reliability across thousands of videos. We addressed these with channel-based concurrency controls, content chunking for large transcripts, comprehensive error handling, and state tracking to resume interrupted processing.
How does the Universal Content Adapter pattern enable expansion?
The pattern standardizes how content is extracted, normalized, processed, and stored, making it simple to add new platforms like LinkedIn, Twitter, or technical blogs with just a few lines of code. This design ensures all content sources go through the same insight processor, maintaining consistency while enabling rapid expansion.
What's the projected impact on content creation workflows?
Teams could reduce research time from 60% to 15% of creators’ time while monitoring 800+ channels instead of 25. Content could be 1-2 weeks behind cutting edge instead of 3-6 months, allowing creators to focus on creating engaging learning experiences rather than just trying to stay current.
Why use one-week proof of concept sprints instead of full builds?
Short sprints allow clients to test automation solutions without committing to a full build, letting them see real results and determine if the approach fits their needs before making a larger investment. This reduces risk and allows teams to experience automation benefits before committing significant resources.
What's the key lesson about balancing automation and human expertise?
Automation should scale research capabilities so experts can focus on higher-level analysis and teaching, not replace editorial judgment. The system isn’t meant to replace human insight but to provide a foundation of processed information that experts can build upon for strategic decision-making.
How can other businesses apply this content intelligence approach?
Any organization that needs to stay current with industry developments can benefit from automated content monitoring. The approach works for competitive intelligence, trend analysis, educational content planning, or market research across any industry where staying current with thought leadership and developments is crucial for business success.
If you want to explore what it’s like to start baking automation into your product, into your workflow, and what it means for your business revenue, then the one-week proof of concept sprint is a great place to start.Visit withseismic.com and book a meeting to get started on your automation journey. In just one week, you can test the waters of automation and see if it’s the right solution for your team—without committing to a complete build that breaks the bank.
Book A Call Today